Sinners reminds me of The Fifth Element in that it is an excellent movie that suffers from teasing you with something bigger than what made it on screen. It could easily be another hour longer but then it would be something different. It is a more-than-but-not-quite-complete movie.
The Middle
I think most people like to think of their place in a creative effort as the beginning or the end or even both, but the reality is that we’re always in the middle.
The most original ideas are still cued by experiences. The most original inventions are still spurred by problems. Nobody starts from zero, and I don’t just mean privilege or connections (though those count too). I mean the basic fact that your inputs came from somewhere, just like you did.
And it goes the other direction too. If we ship the software, people still need to use it. If we build the house, someone still needs to live in it. Our outputs are someone else’s inputs. The chain keeps going.
Once you accept this, something shifts. You don’t need to credit every influence or take responsibility for everything that happens downstream, but being aware that they exist opens your eyes. You start to see how your work can go places you didn’t expect, inform decisions you weren’t part of, generate ideas you won’t be around for. And it lets you rewind. If your “great idea” doesn’t work, it was always just one link in a chain, and you can go back and try a different path.
I think this actually reinforces your contribution rather than reducing it. We tend to put new ideas and great results on a pedestal and treat everything in between as an unavoidable burden. But if it’s all in between, if there is no pristine beginning or triumphant end, just the middle, then you have permission to appreciate and invest in the whole process. This may not get you on the front page or in the corner office, but I think it’s a clearer path to fulfillment and happiness
Look Up First
If you put an architect or designer in an unfamiliar space and take a blindfold off, the first thing they’re likely to do is look up. They’re looking for load-bearing walls. For structure. For constraints.
They might not even be able to tell at a glance. But it’s so important that it’s worth a try. Why? Because it instantly reduces the number of possibilities from near-infinite to something tangible. The pattern recognition finds some surface area to grab onto. Ideas start to get bounced at the door, and the ones that don’t get bounced find space to flourish.
Point an experienced engineer at a codebase and they’re doing the same thing. What frameworks are you using, and which parts are you actually using? What are people depending on? What are your interfaces, your standards?
Not what version of the language it’s written in. Not tabs versus spaces. Those matter eventually, but not on day one. On day one, you need to know the shape of the thing, not the texture.
You don’t need the full blueprint in your head, but you need to know the important parts. You need to know which metaphorical walls you can drill into or knock down and which carry the roof or have plumbing and will blow your budget if you open them up.
One powerful way to do this: look at the abstractions the system makes. You can see which ones held up, which needed workarounds or patching. Which added value. What customers are relying on. What you can and can’t move or remove. The abstractions that survived are load-bearing now—whether they were good bets or just bets that got stuck.
If you can’t point to which code is load-bearing in your system, you don’t understand your system—even if your goal is to tear it down.
52 Word Review: One Battle After Another
One Battle After Another was well-written, well-paced, well-cast, well-acted and well-shot, and yet felt completely forgettable and somehow unoriginal. There were echoes of Tarantino, Terminator 2, Easy Rider and many others, but that’s all it felt like. This might be an accomplishment for other directors but for Anderson it was a disappointment.
The Fantasy of Always and Never
One of the patterns I picked up during my freelancing years was to gently probe any time a client made an absolute statement. “We always do X” or “Y never happens.” These were usually non-technical clients describing their business processes, and I needed to understand them well enough to build software around them.
Honestly, I can’t remember a single one of those statements holding up to any scrutiny. Most fell apart with a single question. “What if Z happens?” “Oh, in that case, we do this other thing.” Almost none of them survived two or three follow-ups. It wasn’t that people were lying or even wrong, they just had a mental model of how things worked that was cleaner than reality.
This matters a lot when you’re building abstractions. When you create a shared component or a unified data model, you’re betting that these things really are the same. That they’ll change together. That the commonality you see today will hold tomorrow. Sandi Metz said “Duplication is far cheaper than the wrong abstraction.” I’d take it further, you need to be really certain an abstraction is right, or it’s probably wrong.
Abstractions and DRY are, in a sense, intentional single points of failure. That’s not to say they’re bad (I build them all the time), but it’s worth keeping in mind. You are hitching a lot to the same post. If you try to abstract physical addresses to cover all addresses everywhere, you’re left with basically zero rules because they’re all broken somewhere. Same for names, medical histories, pretty much any taxonomy that involves humans.
So now when I’m looking at a potential abstraction, I try to pressure-test it. “Users always have an email address” is fragile, there’s probably an exception lurking somewhere. “Users usually have an email address, and we handle it gracefully when they don’t” is something you can build on. If your abstraction can’t survive that kind of flex, it might not be an abstraction at all, just a few things that happen to look similar, until they don’t.
Baseball Hall of Fame 2026
Carlos Beltrán – Weak Yes
Andruw Jones – Weak No
Chase Utley – No
Alex Rodriguez – Strong Yes
Manny Ramirez – Strong Yes
Andy Pettitte – No
Félix Hernández – Weak No
Bobby Abreu – No
Jimmy Rollins – Weak No
Omar Vizquel – Weak No
Dustin Pedroia – No ?
Mark Buehrle – No
Francisco Rodríguez – No
David Wright – No
Torii Hunter – Weak No
Cole Hamels – No
Ryan Braun – No
Alex Gordon – No
Shin-Soo Choo – No
Edwin Encarnación – No
Howie Kendrick – No
Nick Markakis – No
Hunter Pence – No
Gio Gonzalez – No
Matt Kemp – No
Daniel Murphy – No
Rick Porcello – No
I’ve added strong and weak to a few this year. The weak ones I could be probably convinced to switch my vote or might change it with a different set of options.
If my vote counted, I would hate to actually vote against Pedroia, he was one of my favorite players and had a HOF-trajectory career that was cut short by injury.
Where I’m going against the grain: Jones was very good, but just not best-of-the-best. Utley was very popular, but had a few good years early in his career. Pettitte was a reliable workhorse. Both had one meaningful league-leading stat in their whole career, but if they were on small market teams we’d barely remember them.
Hernández just doesn’t quite make the cut for me, along with Hunter. Rollins and Vizquel are tough calls because they were both good contributors, great defenders, and important pieces of their teams.
My New Editor
Google has a concept called “Readability” which usually means you can write and review code of a certain language in the accepted style. When I first joined Google it seemed bureaucratic but I think it strikes a good balance and the languages I have readability in I feel pretty confident that I can write things that will incorporate the style decisions, and the languages I don’t have it, I don’t have that confidence.
A couple of months ago I had an idea that this concept might be useful at a higher level. Instead of Go or TypeScript, what if there was Readability for concepts like security, or maintainability? I started chatting with AI and eventually ended up on what has been a very enjoyable project. It’s not “readability for maintainability” like I thought, nor is it about certification or iron-clad rules, but it’s become a growing repository of thoughts, stories, and observations. I’ll get into more about the process in the future.
I’ve gone back and forth about sharing it here, not because it’s embarrassing but because of the AI aspect. I think it’s been an absolutely fantastic tool for editing and organizing these thoughts and notes, and prompting me for topics to write on, and I love just being able to write a draft and have it come out as something built a bit better. Much of it is my words exactly, but rearranged or glued together into a better structure.
So far 100% of this blog, including this post, has been hand-written by me, I’ve used AI to review the past few posts and made some revisions based on feedback but none of it was written by an AI. I’m now in a position where my choices are to share AI-assisted content, rewrite it myself to satisfy some arbitrary rule, or not share it at all. I don’t like the last option, and the second option seems kind of foolish, so I’m going with the first one and I’m going to tag these posts as #ai-assist for transparency. Where I’ve only used it for feedback I’ll use #ai-review.
The AI isn’t doing anything a good editor wouldn’t do. All of the thoughts, examples, principles and stories are mine (or credited where due). To me, that’s not slop. I hope people judge the content based on what it’s saying rather than the tools involved, but I respect the sensitivity people have towards these tools and don’t want to misrepresent things.
Personal Computing Returns
I’ve been doing a lot of AI-assisted coding both at work and at home lately, and am noticing what I think is a positive trend. I’m working on projects that I’ve wanted to do for a while, years in some cases, but never did. The reason I never did them was because they just didn’t seem like they were worth the effort. But now, as I become a better vibe coder, that effort has dropped rapidly, while the value remains the same. Even further, the value might actually be more, because I can take it even beyond MVP levels and get it to be really useful.
Case in point: I do a lot of DIY renovation work and woodworking (though not enough of the latter). I use a lot of screws and other hardware, and it can be very disruptive to run out. I try to stay organized and restock pre-emptively, but it’s easy to run out. What if there was an app that was purpose-built for tracking this, that made checking and updating inventory as simple as possible, and made it easy to restock? Even better, what if it was written exactly how I track my screws, and had all of the defaults set to the best values for me? Better still, what if it felt like the person who wrote it really understood my workflow and removed every unnecessary click or delay?
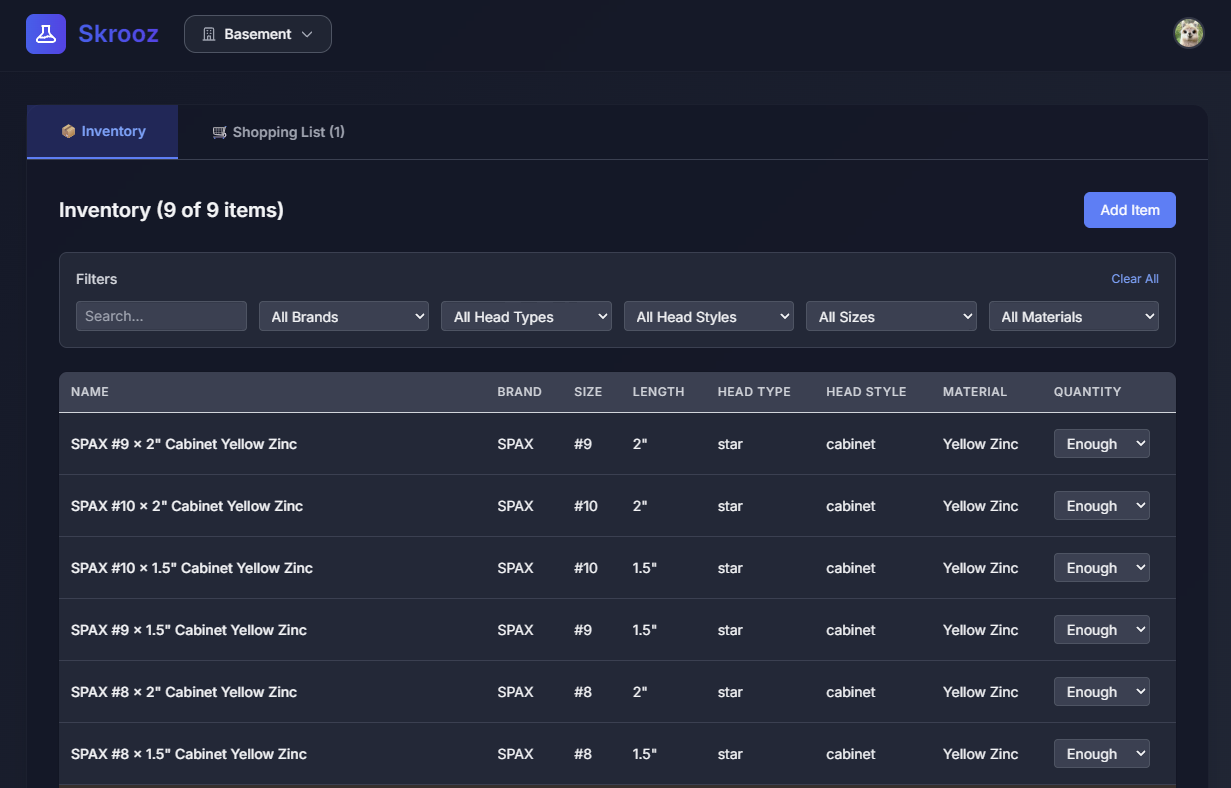
Anyone familiar with app development knows that once you get into the domain-specific details and UX polish necessary to take something from good to great, the time really skyrockets. Screws have different attributes than nails, or hinges, or braces, or lumber. People do things in different ways, and if you miss one use case, they won’t use it. If you cover everything, it’s hard to use and doesn’t feel magical for anyone. You could knock out a very basic version in a few nights, maybe 10 hours, but this wouldn’t do much more than a spreadsheet, which is probably what you’ll go back to as soon as you find some bug or realize you need to refactor something. To make this thing delightful you’re likely in the 50-100 hour range, which is maybe in the embarrassing range when you tell your friends you just spent a month of free time writing an app to keep track of how many screws you have in your basement.
With the current crop of tools like Claude Code and Gemini CLI, that MVP takes 20 minutes, and you can do it while watching the Red Sox. Another hour and it’s in production, and starting to accrue some nice-to-have features, even if the Rays played spoiler and beat the Sox. It works great on desktop and mobile, it safely fits on the free tiers of services like Firebase and Vercel so it’s basically maintenance-free. One more hour while you’re poking around YouTube and you’ve got a fairly polished tool you’re going to use for a while.
I think most people probably have a deep well of things they’d like to have, that never made any financial sense, and probably aren’t interesting to anyone else. We’ve probably even self-censored a lot of these things so we’re not even coming up with as many ideas as we could. But when the time/cost drops by 90% or more, and you can take something from good to great, and have it tailored exactly to you, it’s a whole new experience.
The term “personal computing” went out of style decades ago, and now it feels like we’re all doing the same things in the same way with the same apps, but maybe it’s time to start thinking for ourselves again?
Java 15 though 25 Catchup
Continuing my previous post, let’s pick up the Java story where we left off…
Java 15 (Sept 2020)
Sealed Classes
A nice organizational tool. Not very handy for my personal projects but definitely useful across a large org.
Java 16 (March 2021)
Stream.toList()
Not much else in this release besides this minor but more readable improvement.
Java 17 (Sept 2021, LTS)
Nothing really new here just polish and finalizing things. It looks like this might be the dominant stable version in many enterprises and the baseline for open source right now.
Java 18 (March 2022)
Simple Web Server
This might be very useful for my prototypes. It wasn’t hard to do before but if this works with whatever is a good basic HTTP/API framework these days then it’s great that it’s built-in.
@snippet in Javadoc
I do actually comment my personal code fairly well (if I’m submitting it, even to a private repo) so this seems nice.
Java 19 (Sept 2022)
Record Patterns
I’m only reading some examples of this and definitely want to try it but it seems like it could be pretty clean. It’s kind of like Go interfaces, which I’m a fan of (though I wish they had a different name since they’re flipped backwards in some regards to older language’s interfaces).
Virtual Threads
Very interesting. I do tend to do a lot of concurrency in my projects so I’m definitely going to be spending some time with this one.
Java 20 (March 2023)
Scoped Values
ThreadLocals aren’t difficult per se but they are weird and easy to misuse. Streamlining the easiest usages of them seems like a win.
Java 21 (Sept 2023, LTS)
String Templates
This syntax seems like it might be a little too streamlined for readability, especially on review, but that seems solvable with tools so I’ll wait and see if I like these.
Structured Concurrency
I’ve rolled my own versions of this very useful concept many times so it would be great if this could standardize that.
Sequenced Collections
On the one hand this seems like a nice taxonomic update, but it also seems like it could be easily confused with Sorted Collections, but maybe that’s just me.
Java 22 (March 2024)
Statements before super(…) / this(…) in constructors
Ooh, this seems like it’s a bigger change than it appears on the surface. I have vague recollections of some significant class-layout workarounds for this limitation, but I’m also getting a Chesterton’s Fence vibe here in why this limitation existed in the first place.
Stream Gatherers
A few projects in my queue are data/statistics-based so this might come in handy, if third-party libraries don’t already handle this well enough.
Java 23 (Sept 2024)
Implicit classes & instance main
I never really had any issues with this boilerplate because the IDE always wrote it and it never really changed after that, but it’s cool that it got streamlined.
Java 24 (March, 2025)
Key Derivation Function API
Figuring out how to get signed APIs working almost always feels like it’s harder than it should be, so I’m all in favor of standardizing it. I’m not sure what the long-term impact is here because I’m sure the next great crypto approach will have some structural reason you can’t use this…
Java 25 (September 2025?, LTS)
The next LTS, nothing really major on the menu but a number of finalizations which will be nice.
Final Thoughts
I started this mini research project thinking there were going to be more things like lambdas which I thought were going to maybe take the language away from what I always liked about it, but that definitely doesn’t seem to be the case. There are a ton of streamlined features that work well within the same mental model and “spirit” of the language. I’m really looking forward to digging in and using almost all of them.
Java 8 though 14 Catchup
After a long hiatus, I’ve been increasingly motivated to do a few tech side projects. Working at Google everything there is Google-specific, or at least Google-flavored, and even if I wanted to use the same stuff I mostly couldn’t. My primary language there is Go, which is fine, but I’m going back to Java, at least for the backend/offline stuff, for now. I’m in the process of picking a stack, and starting with the language.
The last real Java project I did was Java 7, which was already aging at that point but we were going for stability and Java 8 was only a few months old when we started. Java 24 just came out, so I’ve missed 17 versions! I could just jump in but I haven’t really followed the language at all aside from some tinkering over the years and I was probably not really taking advantage of anything new. I think it would be fun to roll forward and read up on each version, seeing the highlights of what each version added or changed.
I’m mostly interested in the language aspects and the core libraries. I’m not that concerned with things like GC versions and improvements. Those are very important but for my hackery it’s unlikely I’ll need to get that far into the internals. Also, I’m going to discuss preview features mostly where they first appeared, not the iterations and finalizations in subsequent releases.
Java 8 (March 2014)
Lambdas
Now I remember why we didn’t upgrade, lambdas seemed a bit daunting and I don’t know if the tooling (Eclipse + Lombok at the time) had really caught up yet. I’m still not a huge fan of lambdas in any language, I think they are nice shortcuts but I’d prefer cleaner-delineated blocks. In JS where I use them the most I almost always define a function separately and then reference that, unless it’s just a line or two.
Type Annotations
I love annotations when used judiciously, @NonNull seems cool but I could see it getting out of control so I’ll have to wait and see how it’s used in the real world.
Optional
I’ve used this a lot in C++ and it definitely fits my be-explicit style.
Streams
A companion to lambdas, these will look strange at first but i use this pattern a lot in JS so it will probably feel right eventually.
Java 9 (Sept 2017)
JDK Modularization
This looks like a big deal, but probably more on the enterprise level than personal projects.
Collection factory methods (List.of, Set.of, Map.of)
Very nice ergonomics, looking forward to that especially for hacky prototype stuff.
Java 10 (March 2018)
Local-variable type inference (var)
Lombok had this but I didn’t use it too much. It’s really dependent on your tooling, as it adds complexity to refactoring which is one of the things I loved most about Java (and hopefully holds up!). I’m curious how this looks in real code.
Unmodifiable collection copies
More ergonomic polish that I’ll likely be using for hacking things up where hardcoding is common.
Java 11 (Sept 2018, LTS)
Looks like this was the first true LTS vesrion? Nothing groundbreaking on a language level, just some ecosystem cleanup.
Java 12 (March 2019)
Improved switch
Kind of cool. Looks like a strictish lambda variant.
Java 13 (Sept 2019)
Text Blocks
Pretty good, basically parity with most other languages at this point.
Java 14 (March 2020)
Records
Interesting. I always preferred a pretty clean “bean” structure and used Lombok for the boilerplate so this probably wouldn’t make my code look that much different but it’s always nice to be able to build on core concepts instead of just conventions.
Pattern Matching for instanceof
Makes sense. I found that needing to introspect/cast (since generics) was almost always a failure of the APIs involved but sometimes they were still unavoidable. I used them when trying to make things more magical and automatic and bury complexity behind a clean interface.
Helpful NullPointerExceptions
OMG how did this take 14 versions to happen.
Thoughts So Far
So that was about 6 years and some pretty decent improvements overall. I don’t want Java to go the way of C++ and just get more and more complex with a never-ending stream of new ways to do things, even if they are probably better. I like my Java to be boring and predictible, very easy to read, very easy to refactor, and very easy to hand off. Not all of these are great for that, notable lambdas and type inference but we’ll see how it goes.